消息中间件
一、MQ介绍
1、什么时MQ,有什么用
MQ(message queue),消息队列。message是在不同应用程序实践传递的数据,queue将消息以队列的形式存储起来,并且在不同的应用程序之间进行传递。生产者(producer)发送消息,消费者(consumer)接收消息。
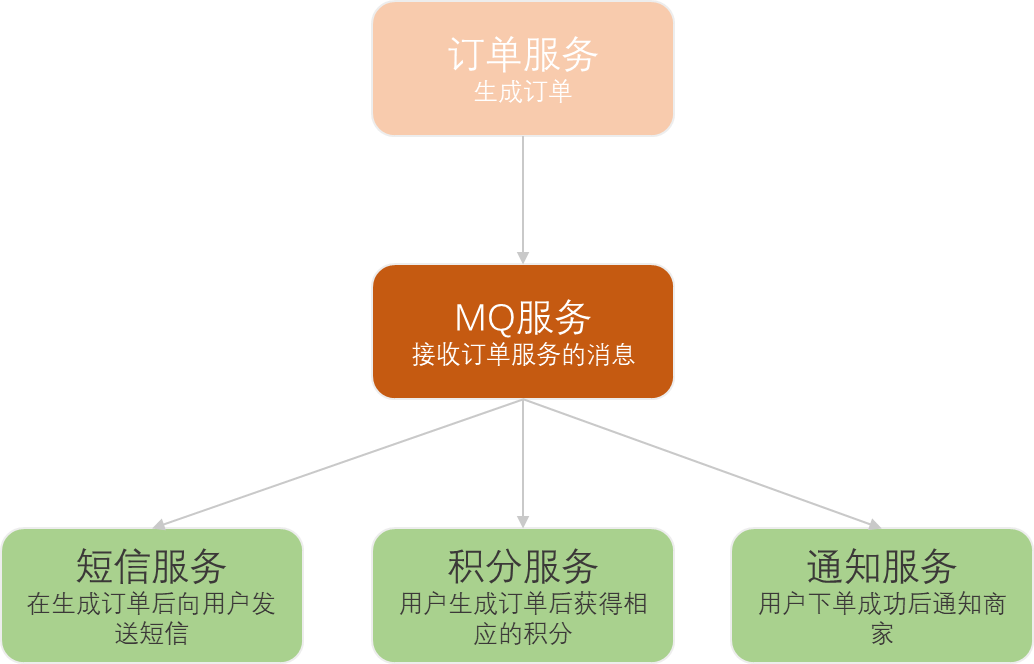
在上面这个例子中,订单服务在生成订单后,发送消息到MQ,短信服务、积分服务、通知服务在监听到MQ变化后接收消息,进行下一步的处理。
在这个业务中,MQ中间件应该要起到什么作用呢?
解耦:Producer和Consumer都只跟中间件进行交互,而不需要互相进行交互。这意味着,在Producer发送消息时,不需要考虑有没有Consumer或者有多少个Consumer。反之亦然。甚至,即便Producer和Consumer是用不同语言开发的,只要都能够与MQ中间件正常交互,那么他们就可以通过MQ中间件进行消息传递。
异步:消息并不是从Producer发送出来后,就立即交由Consumer处理,而是在MQ中间件中暂存下来。等到Consumer启动后,自行去MQ中间件上处理。也就是说,错开了Producer发送消息和Consumer消费消息的时间。
削峰:有了MQ做消息暂存,那么当Producer发送消息的速度与Consumer处理消息的速度不一致时,MQ就能起到削峰填谷的作用。
2、主流MQ产品对比
二、消息队列的流派
1. 有broker
重topic:kafka、rocketMQ、activeMQ
整个broker,依据topic来进行消息的中转。在重topic的消息队列里必然需要topic的存在
轻topic:rabbitMQ
topic只是一种中转模式
2. 无broker
在生产者和消费者之间没有使用broker,例如zeroMQ,直接使用socket进行通信。
三、Kafka
1. Kafka的基本概念
kafka是一个分布式的,分区的消息服务。它提供了一个消息系统应该具备的功能,但是却有着独特的设计。可以这样来说,kafka借鉴了JMS(Java Message Service)规范的思想,但是并没有完全遵循JMS规范。
2. 创建topic
kafka4.0
# 启动容器
docker run -d --name broker apache/kafka:latest
# 设定工作目录,进入容器内
docker exec --workdir /opt/kafka/bin/ -it broker sh
# 创建topic,4.0不用zookeeper就这样启动
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test-topic
# 4.0之前
./kafka-topics.sh --create --zookeeper zookeeper地址 --replication-factor 1 --partitions 1 --topic test
# 查看所有的topic
./kafka-topics.sh --bootstrap-server localhost:9092 --list
3. 发送消息
kafka自带了一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以命令行直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当做成一个独立的消息。使用kafka的发送消息的客户端,指定发送到kafka服务器地址和topic
./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test-topic把消息发送给broker中的某个topic,打开一个kafka发送消息的客户端,然后开始用客户端向kafka服务器发送消息。
4. 消费消息
对于consumer,kafka携带了一个命令行客户端,会将获取到的内容在命令中进行输出,默认是消费最新的消息。使用kafka的消费者消息客户端,从指定kafka服务器的指定topic中消费消息
打开一个消费消息的客户端,向kafka服务器的某个主题消费消息
方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test方式二:从头开始消费
# 从开始消费消息
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic --from-beginning5. 关于消息的细节
生产者将消息发送给broker,broker会将消息保存在本地的日志文件中。
/tmp/kraft-combined-logs/test-0/00000000000000000000.log消息的保存是有序的,通过offset偏移量来描述消息的有序性。
消费者消费消息时也是通过offset来描述当前要消费的消息的位置。
6. 单播消息
在一个kafka的topic中,启动两个消费者,一个生产者,问:生产者发送消息,这条消息是否同时会被两个消费者消费?
如果多个消费者在同一个消费组,那么只有一个消费者可以收到订阅的topic中的消息,换言之,同一个消费组中只能有一个消费者收到一个topic中的消息。
./kafka-console-comsumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test7. 多播消息
不同的消费组订阅同一个topic,那么不同的消费组中只有一个消费者能收到消息。实际上也是多个消费组中的多个消费者收到了同一个消息。
./kafka-console-comsumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test
./kafka-console-comsumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup1 --topic test8. 查看消费组及信息
# 查看当前主题下有哪些消费组,没有显式指定消费组id会有默认的随机消费组
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
console-consumer-74284
console-consumer-80820
# 查看消费组中的具体信息:比如当前偏移量、最后一条消息的偏移量、堆积的消息数量
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGroupGROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-80820 test 0 - 7 - console-consumer-b2f852a9-12c9-48ed-bcf0-e6fc97807524 /127.0.0.1 console-consumer
CURRENT-OFFSET:当前消费组的已消费偏移量,最后被消费的消息的偏移量
LOG_END_OFFSET:主题对应分区消息的结束偏移量(HW),最后一条消息的偏移量
LAG:当前消费组未消费的消息数,积压了多少条消息
四、kafka主题、分区的概念
1. 主题topic
主题-topic在kafka中是一个逻辑的概念,kafka通过topic将消息进行分类。不同的topic会被订阅该topic的消费者消费。
如果说这个topic中的消息可能非常非常多,多到需要几个T来存,因为消息是会保存到log日志文件中。为了解决这个文件过大的问题,kafka提出了partition的概念。
2. 分区Partition
1)分区的概念
一个主题中的消息量是非常大的,因此可以通过分区的设置,分布式存储这些消息。比如一个topic创建3个分区。那么topic中的消息就会分别存放在这三个分区中。
分区存储,可以解决同意存储文件过大的问题
提供了读写的吞吐量:读和写可以同时在多个分区中进行
可以分布式存储
可以并行写
2)创建多分区的主题
# 创建一个两个分区的主题test1
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic test13.kafka中消息日志文件保存的内容
000000000.log:这个文件保存的就是消息
__consumer_offsets-49:kafka内部创建了__consumer_offsets 主题包含了50个分区。这个主题用来存放消费者消费某个主题的偏移量。
存放数据内容是:key是consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据。
kafka默认分配50个分区(可以通过offsets.topic.num.partitions设置),通过hash(consumerGoupId) % \_\_consumer_offsets主题的分区数可以选出consumer消费的offset要提交到__consumer_offsets的哪个分区
文件中保存的消息,默认保存七天。七天后消息会被删除。
五、kafka集群操作
1. 搭建kafka集群
2. 副本的概念
在创建主题时,除了指明主题的分区数以外,还指明了副本数。副本是为了为主题中的分区创建多个副本,多个副本在kafka集群的多个broker中,会有一个副本作为leader,其他是follower。
leader:kafka的写和读操作,都发生在leader上。leader负责把数据同步给followe。当leader挂了,经过主从选举,从多个follower中选举出一个新的leader(raft)。
follower:接收leader的同步数据
isr:可以同步和已同步的节点会被存入isr集合中。如果isr中的节点性能较差,会被踢出isr集合。
集群中有多个broker,创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存储),可以为分区创建多个副本,不同的副本存放在不同的broker中。
3. 关于分区消费组消费者的细节
一个kafka集群有两个broker,每个broker中有多个partition。一个partition只能被一个消费组里的某一个消费者消费,从而保证消费顺序。kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序。一个消费者可以消费多个partition。
消费组中消费者的数量不能比一个topic中的partition数量多,否则多出来的消费者消费不到消息。
六、Go操作kafka
1. ack
在同步发送的前提下,生产者在获得集群返回的ack之前会一直阻塞。分别有下面三种配置:
ack=0:kafka集群不需要任何的broker收到消息,就立即返回ack给生产者,最容易丢消息,效率最高。
ack=1(默认):多副本之间leader已经收到消息,并把消息写入到本地的log中,才会返回ack给生产者,性能和安全性最均衡的
ack=-1/all:等到集群内有超过配置的min.insync.replicas个broker写入本地消息才会返回ack,最安全,但性能最差
七、kafka集群controller、rebalance和HW
1. Controller
集群的controller,负责管理整个集群中的所有分区和副本的状态:
当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
当检测到某个分区的ISR集合发生变化时,由控制器负责为该分区选举新的leader副本。
当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是有controller负责让新分区被其他节点感知。
2. Rebalance机制
前提是:消费者没有指明分区消费。当消费组里消费者和分区的关系发送变化,就会出发rebalance机制。
这个机制会重新调整消费者消费哪个分区。
在触发rebalance机制之前,消费者消费哪个分区有三种策略:
range:通过公式(总分区数/消费组消费者总数)计算某个消费者消费哪个分区。
轮询:轮询消费
sticky:在触发rebalance后,在消费者消费的原分区不变的基础上进行调整。将挂掉的消费者所持有的分区分到剩下的消费者上。如果有消费者挂了,但是没用这种策略就需要重新分配。
3. HW和LEO
LEO(log-end-offset)是某个副本最后消息的消息位置
HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR最小的LEO作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。
八、kafka线上问题优化
1. 如何防止消息丢失
发送方:1)使用同步发送 2)ack是1或者-1/all可以防止消息丢失,如果要做到99.99999%,ack设为all,把min.insync.replicas配置成分区备份数。
消费方:把自动提交改为手动提交。
2. 如何防止消息的重复消费
在防止消息丢失的方案中,如果生产者发送消息后,因为网络抖动,没有收到ack,但实际上broker已经收到了。此时生产者会进行重试,于是broker就会收到多条相同的消息,而造成消费者的重复消费。
解决方案:
生产者关闭重试机制,但是容易造成消息丢失。
消费者解决幂等性消费问题:
幂等性:多次访问的结果是一样的。对于rest的请求(get(幂等),post(非幂等),put(幂等),delete(幂等))
解决方案:
在数据库中创建联合主键,防止相同的主键创建多条记录
使用分布式锁,以业务id为锁,保证只有一条记录能够创建成功
3. 如何做到顺序消费
发送方:在发送时将ack不能设置为0,d使用同步发送,等发送成功再发送下一条。确保消息是顺序发送的。
接收方:消息是发送到一个分区中,只能有一个消费组的消费者来接收消息。
kafka的顺序消费使用场景不多,要想实现顺序消费会牺牲掉性能,可以使用rocketMQ。
4. 消息积压
1)消息积压问题的出现
消息的消费者的消费速度远赶不上生产者生产消息的速度,导致kafka中有大量的数据没有被消费。随着没有被消费的数据堆积越多,消费者寻址的性能会越来越差,最后导致整个kafka对外提供服务的性能很差,从而造成其他服务的访问速度变慢,造成服务雪崩。
2)消息积压的解决法方案
在这个消费者中,使用多线程,充分利用机器的性能进行消费消息。
创建多个消费组,多个消费者,部署到其他机器上,一起消费,提高消费者的消费速度。
创建一个消费者,该消费者在kafka另建一个主题,配上多个分区,多个分区再配上多个消费者。该消费者将poll下来的消息,不进行消费,直接转发到新建的主题上。此时,新的主题的多个分区的多个消费者就开始一起消费了。
5. 实现延迟队列的效果
1)应用场景
订单创建后,超过30分钟没有支付,则需要取消订单,这种场景可以通过延时队列来实现
2)具体方案
kafka中创建相应的主题
消费者消费该主题的消息(轮询)
消费者消费消息时判断消息的创建时间和当前时间是否超过30分钟(前提是订单没支付)
如果是:去数据库中修改订单状态为已取消
如果否:记录当前消息的offset,并不再继续消费之后的消息。等待一段时间后,再次想kafka拉去该offset及之后的消息,继续进行判断,以此重复。